dev diaryWhere to Look Next: Active Perception for Autonomous 3D Reconstruction
The Idea
My SLAM project is built on ORB-SLAM3, which is a passive SLAM system—it provides pose estimation, sparse landmark maps, loop closure, and graph optimization. That worked great for the scope of that project, but throughout development I kept thinking about how I would change things if I were building for different types of production systems. The system just went wherever the camera happened to go. There was no intelligence in the viewpoint selection.
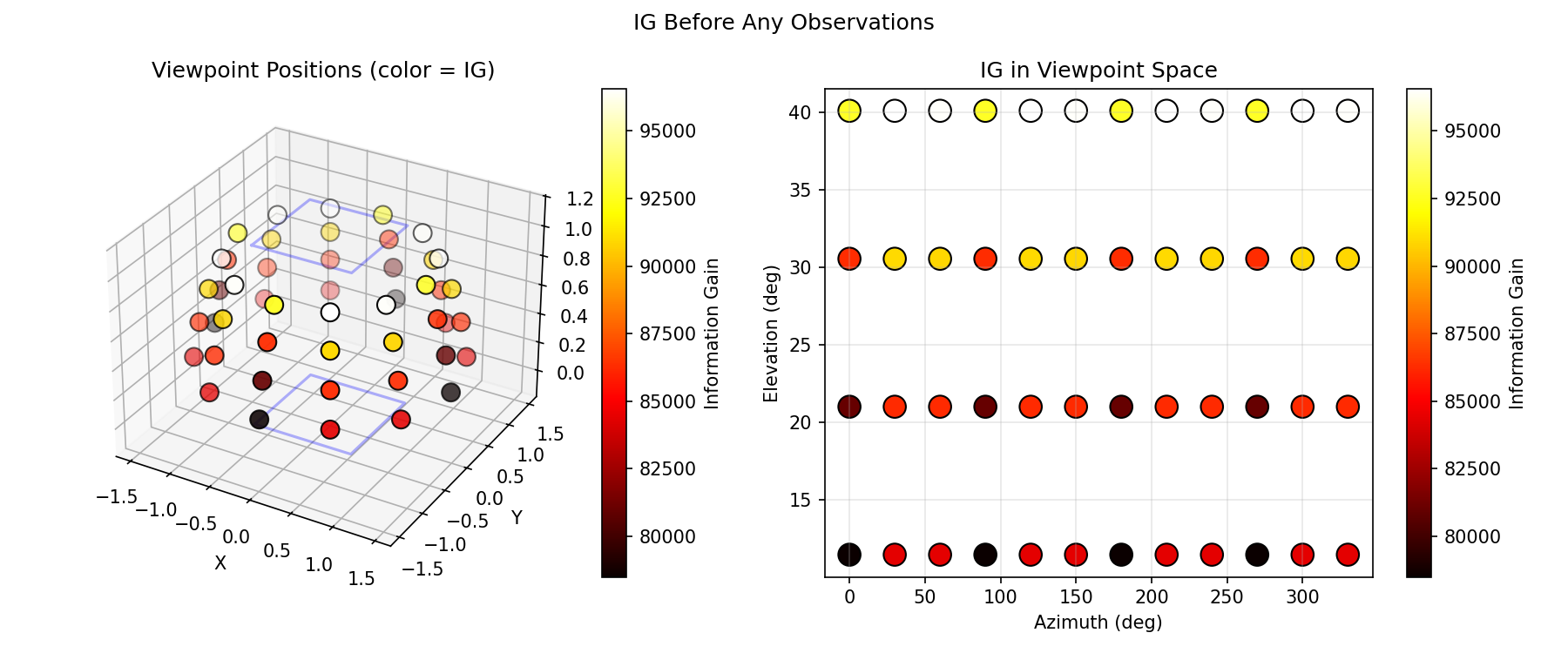
I knew that because there was already a dense TSDF 3D reconstruction in my pipeline, I could make the passive system active by using the map to drive exploration decisions. The process could look something like this: evaluate candidate viewpoints by sampling potential camera poses, raycast through the map from each pose to predict what surfaces you would observe, count the voxels that are currently unknown or partially observed. That gives you expected information gain per pose.
Compute utility for each candidate:
U(x) = expected unknown voxels observed – λ · motion cost
If it's high, move there. If it's low, ignore it. Then plan motion with RRT* or A*, update the map with new observations, and repeat.
It's a pretty simple loop, and I figured I may as well try to implement it—mainly as a theoretical exercise to satisfy my own curiosity about how active perception would slot into a system like ORB-SLAM3.
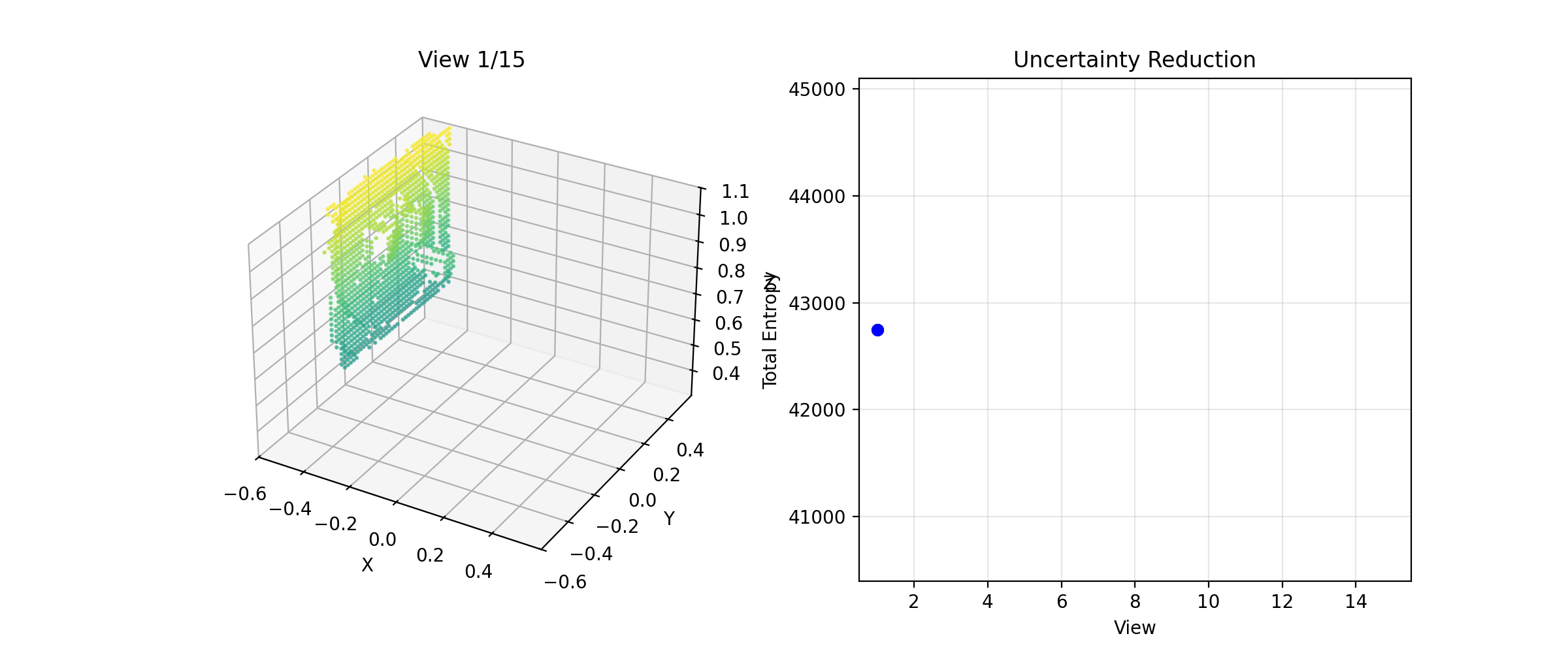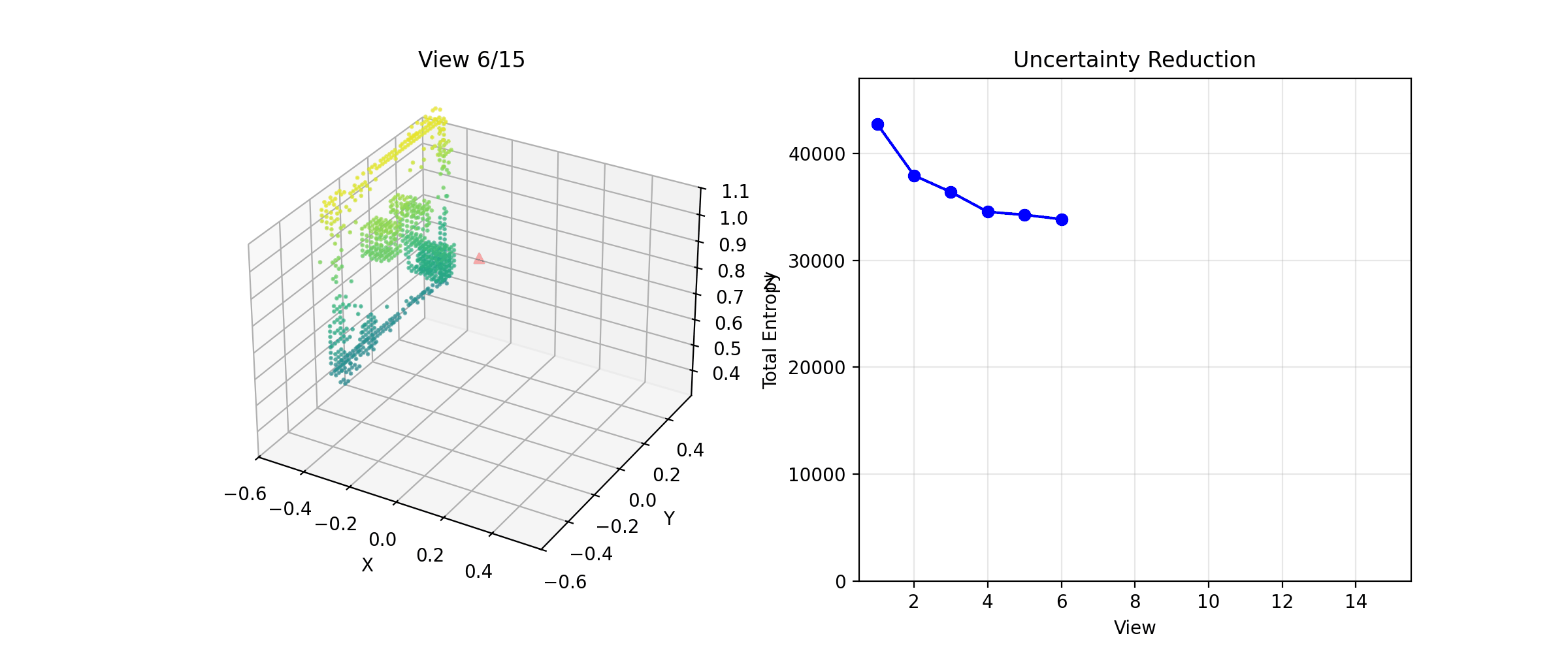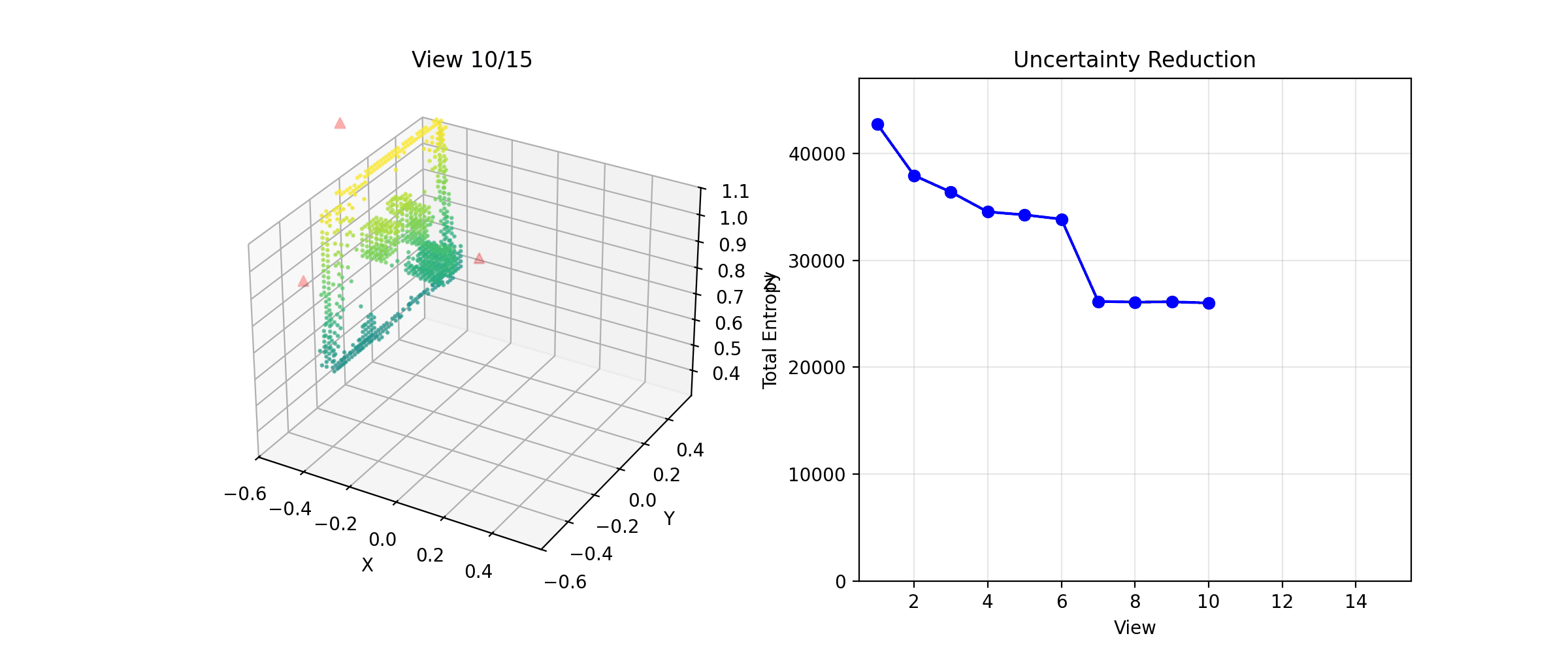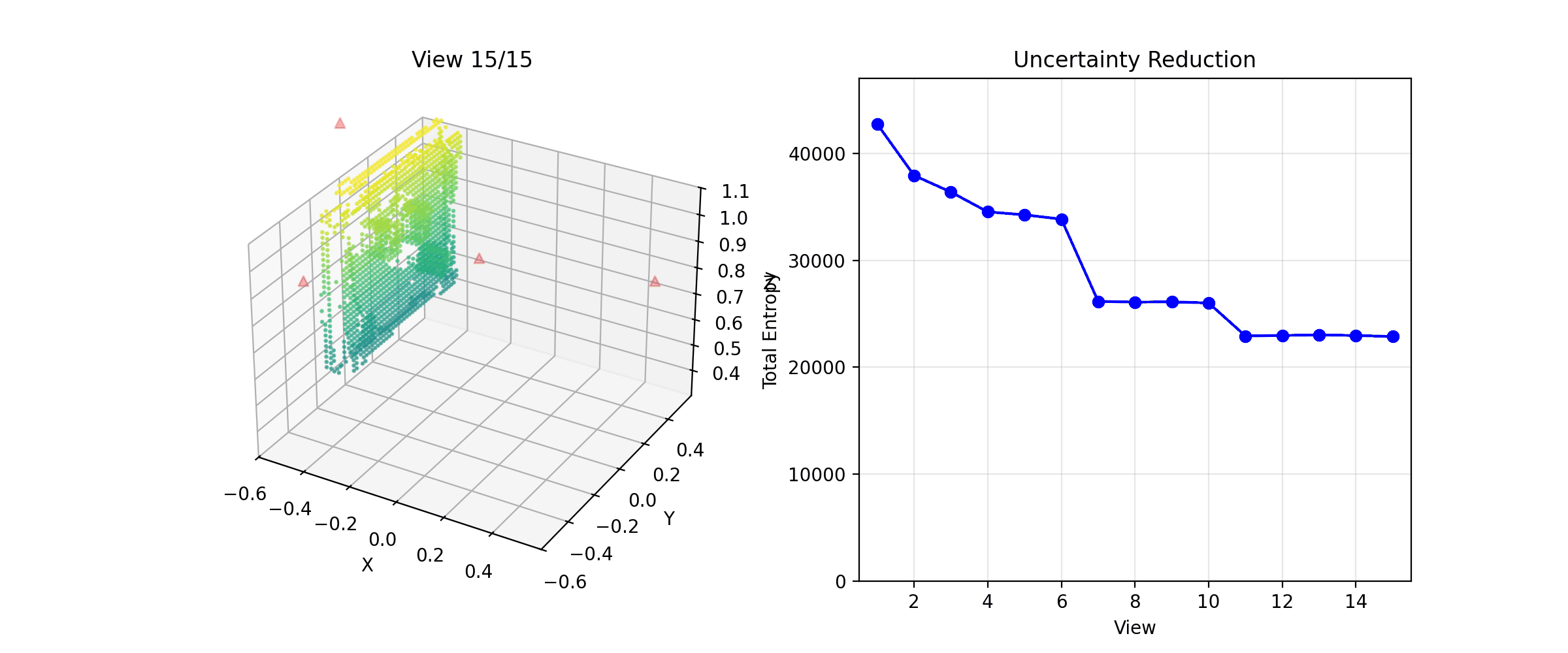
The NBV system building a reconstruction across viewpoints
Why Log-Odds If SLAM is TSDF?
Before getting into the implementation, one design choice worth explaining upfront: I used a Log-Odds occupancy grid instead of TSDF, even though my SLAM project used TSDF.
There are really only two options for the volumetric representation. TSDF gives you much cleaner surfaces and is what you'll see in most reconstructions that need to capture fine geometry in real-time. A Log-Odds system stores the log-odds of each voxel being occupied, you get a probabilistic map of where surfaces are and aren't, and from that, Shannon entropy. The Bayesian update rule is additive and fast, and it handles numerical edge cases cleanly when P approaches 0 or 1. In log-odds space P=0.99L~4.6
The tradeoff is that computing information gain from TSDF requires more work, you have to estimate gain from signed distance values rather than occupancy probabilities, which is less direct. Since this project was already scoped as educational and my experiment environment was a MuJoCo simulation of volumetric shapes on a table, Log-Odds was the right call. Simpler representation, cleaner entropy math, no real downside given the scope.
Getting the Raycasting Right
For each depth image, cast a ray from the camera. Rays that hit a surface mark that voxel as occupied. Rays that pass through voxels on the way to the surface mark those voxels as free. This "free-space carving" is what makes the map useful, without it you just have surface points, not a volumetric understanding of the scene.
MuJoCo's coordinate conventions don't match OpenCV. Azimuth 0 puts the camera at +Y looking along -Y, and elevation is negative when the camera is above the lookat point. I worked out the correct backprojection transform by rendering from a known position and verifying the point cloud came back at the right world coordinates. Once that was sorted the raycasting produced clean geometry.
Initial point cloud before coordinate transform fix
Information Gain
For each candidate viewpoint, I need to estimate how much it would reduce uncertainty in the map. The principled formulation is:
IG(v) = H(map) – E[H(map | z_v)]
In practice: raycast through the current map from the candidate viewpoint, classify which voxels would be observed, compute how much entropy those observations would reduce assuming they resolve uncertainty, and sum it up. It's optimistic—you're assuming each observation fully resolves the voxel—but it's a reasonable approximation for planning.
I also implemented a simpler heuristic baseline: just count the number of unknown voxels visible from the candidate. Faster to compute, less principled, but useful as a sanity check.
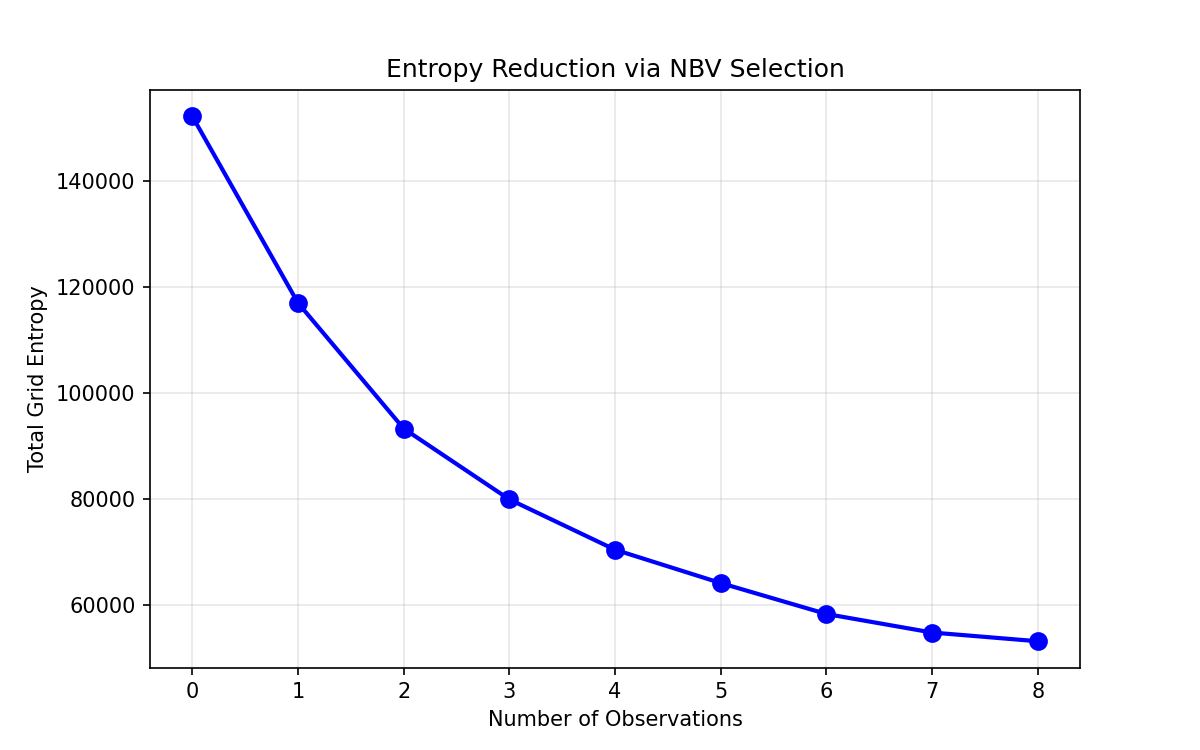
Entropy dropping with each NBV step
Performance was reasonable. With a 2cm resolution and 320x240 virtual images, a single viewpoint evaluated in ~4ms at subsample=4
System Was Working, But Poorly
I had the full NBV loop running but it was performing worse than the random baseline I'd set up as ground truth. I was pretty sure the raycasting was correct, so I assumed the planner was stuck somehow and not exploring the hemisphere properly. I logged the viewpoints being selected.
It was selecting the same viewpoint on repeat. I think the root causes was that Bayesian updates are intentionally weak (l_free = -0.4
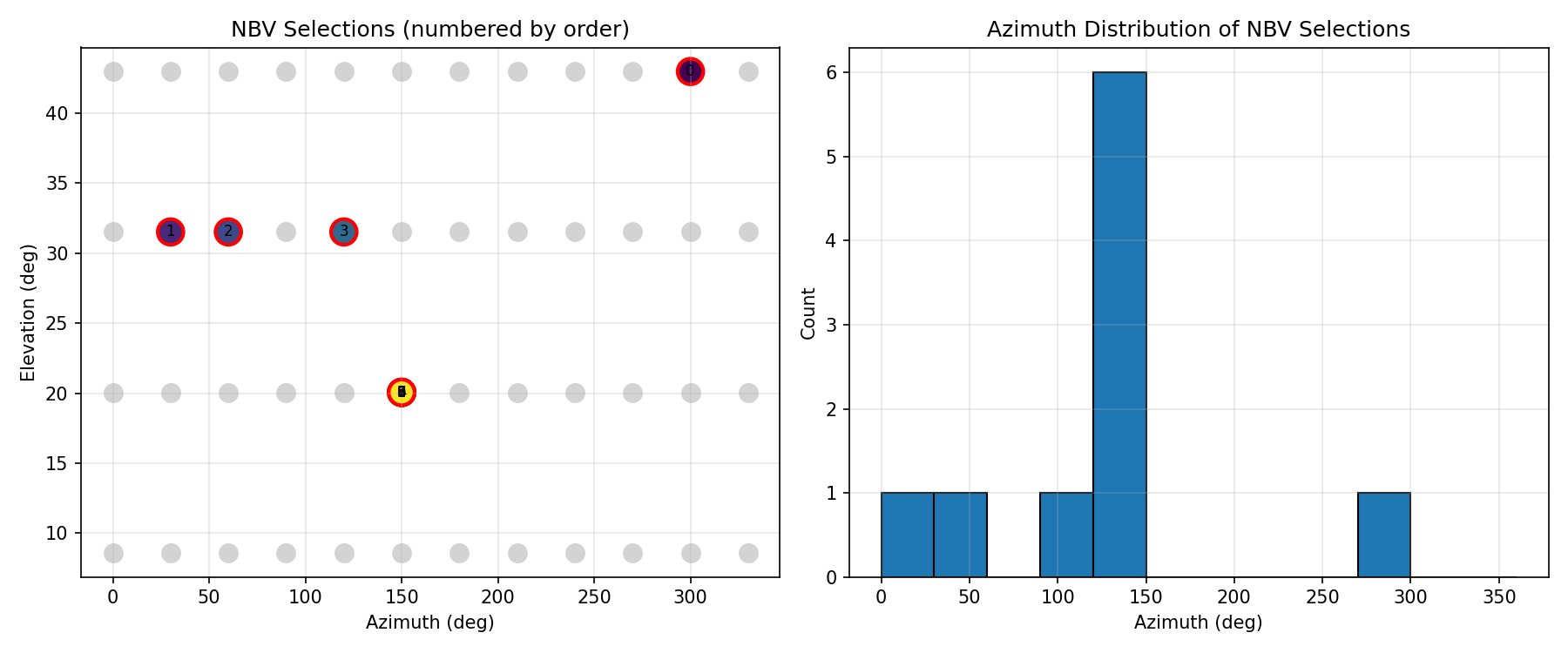
Planner fixating on a single viewpoint
The fix was adding an exploration bonus to penalize recently-visited viewpoints and push the planner toward less-observed parts of the hemisphere. Once that was in, the planner started moving around properly.
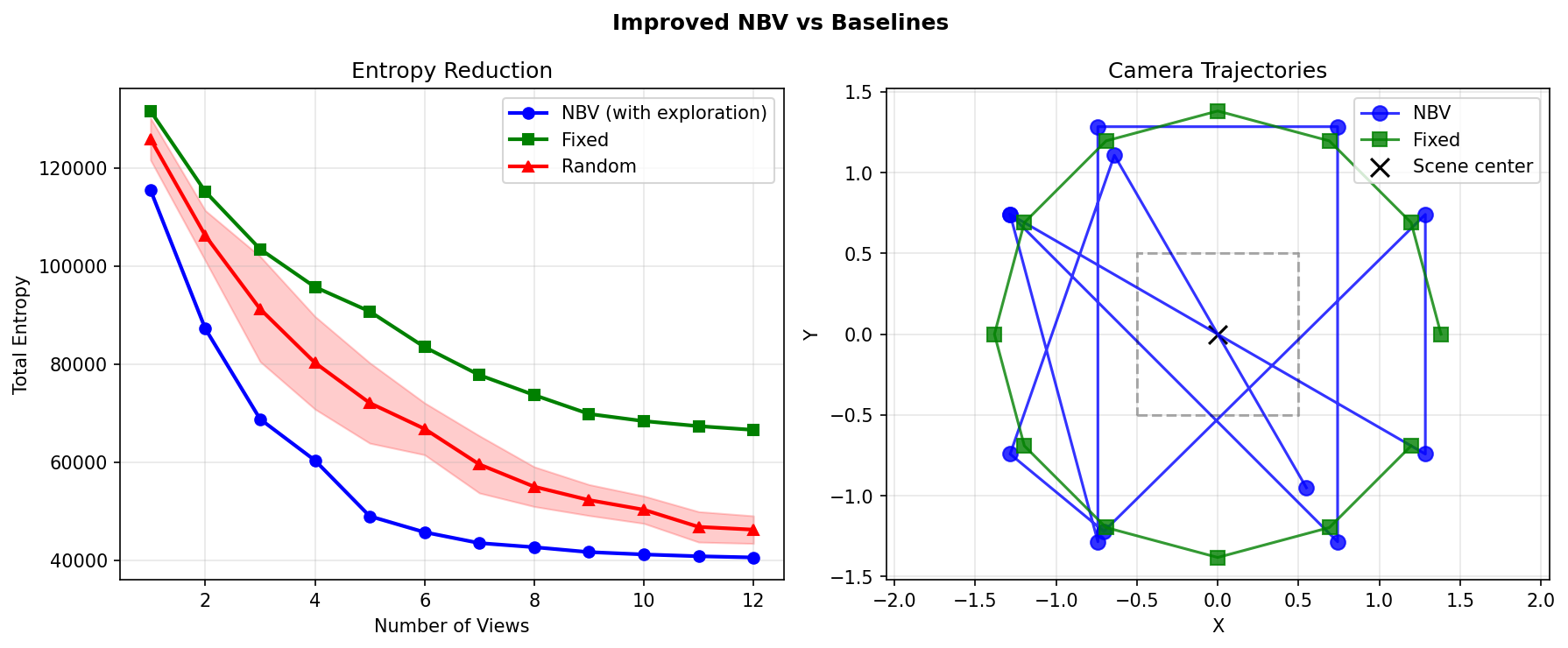
NBV vs random vs fixed after adding exploration bonus
With the exploration bonus, the system achieved 12.3% more efficient information gain than random and 39% better than a fixed sweep.
The Ground Plane Problem
Looking at the reconstructions, there was more noise than expected for a first real run. Increasing fusion density and strengthening the Bayesian updates produced more voxels but not better geometry, which told me the problem was in the data, not the fusion parameters.
I plotted the Z-distribution expecting a small floor contamination. Turns out 70% of observed points were at z < 0.1mgrid_min
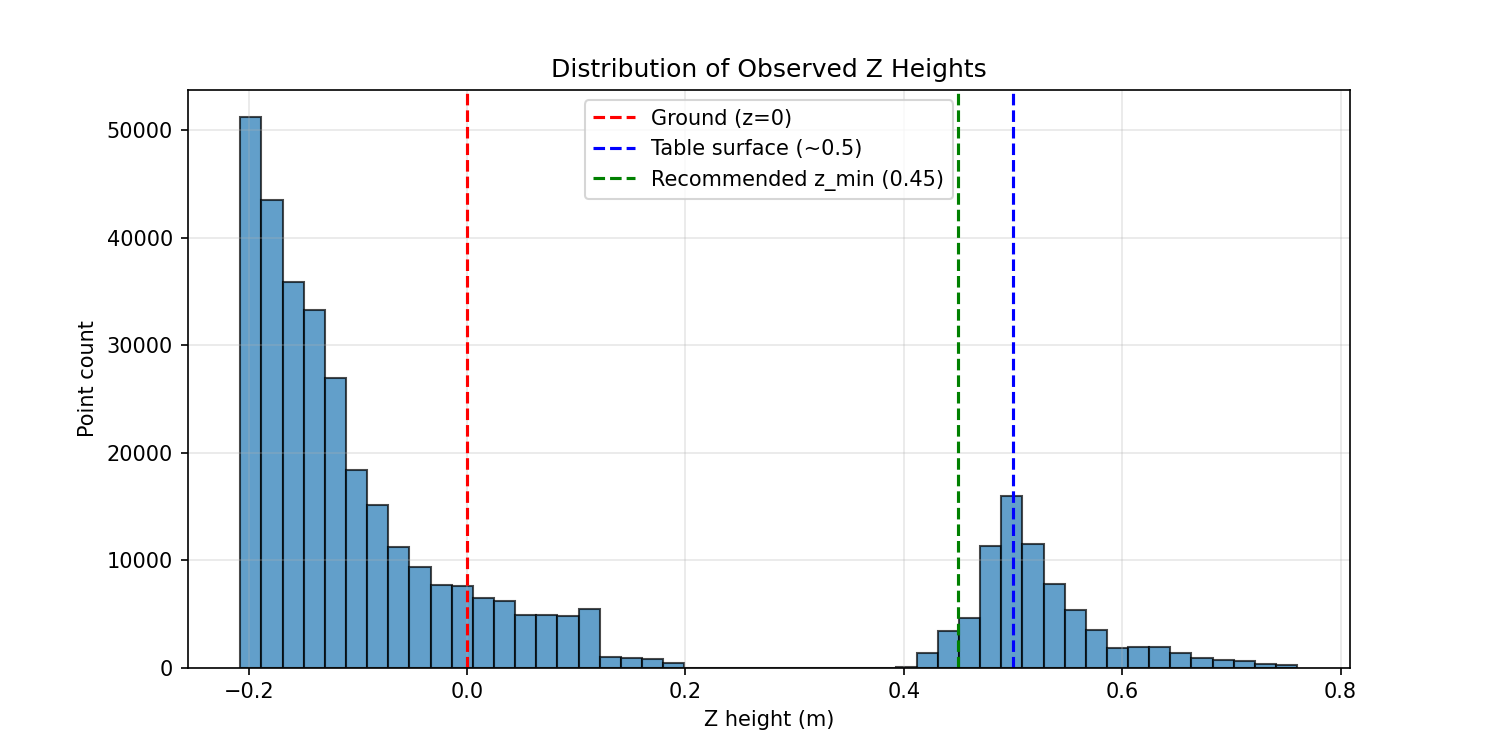
Z-distribution of observed points | 70% below the table
That still left noise from the strong Bayesian updates. With l_occ = 2.0P(occupancy)l_occ=0.85
Weak updates mean slower convergence, which means more views to reach the same certainty. But the quality difference was significant enough that it was worth it. I also added a post-processing pass: higher occupancy threshold (0.8 instead of 0.7) and removal of isolated voxels with fewer than two neighbors.
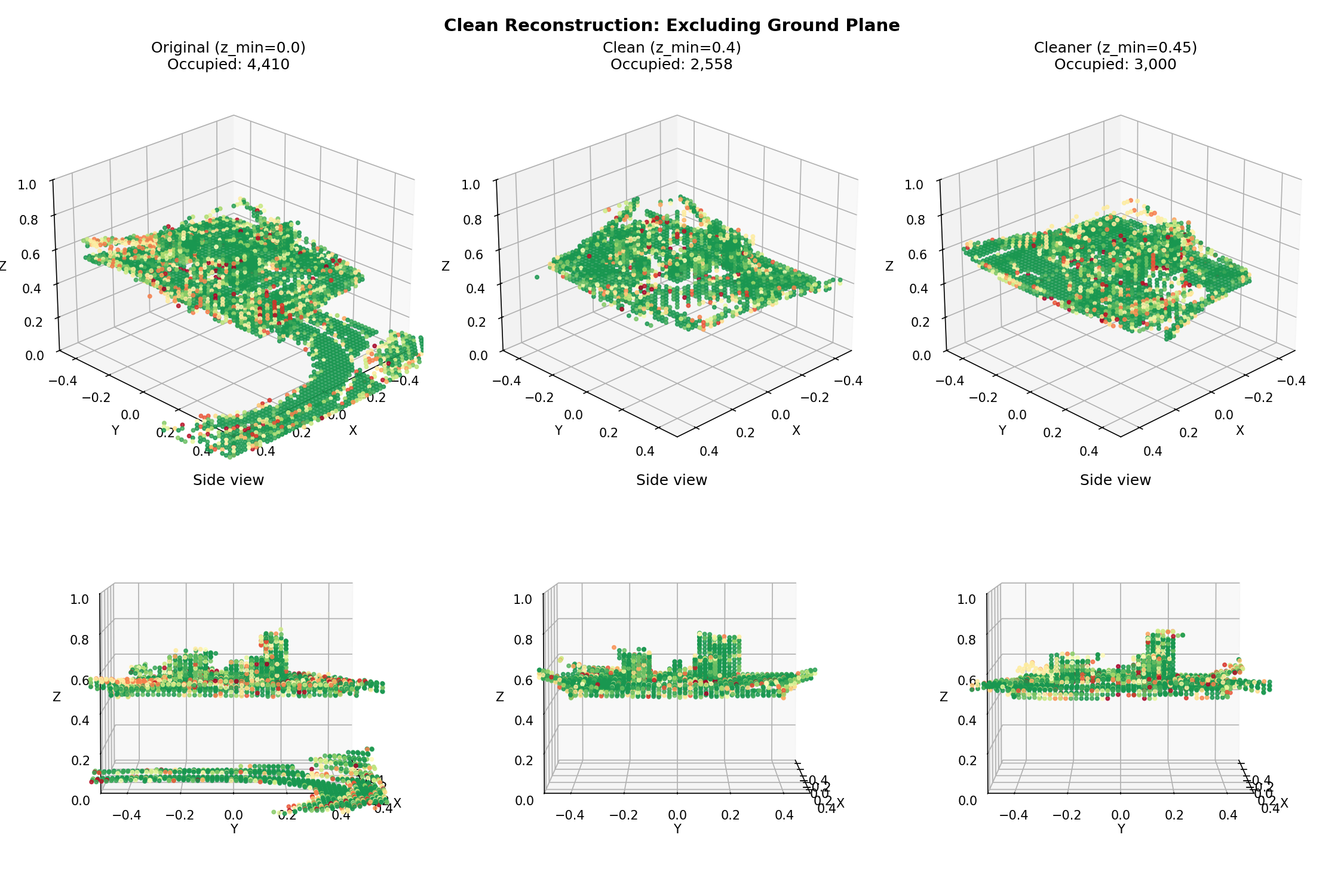
Final reconstruction after fixing ground plane and tuning update strength
Seeing how the myopic exploration-exploitation problem showed up was a pretty cool obersvation from this experiment. That's a problem you obviously see in RL, in the context of reward functions and policy gradient updates. Here it emerged from purely geometric reasoning: a greedy information gain criterion starving itself by fixating on a region it had already partially observed. The fix was the same as it would be in RL, add an exploration bonus, but the mechanism was completely different.
I think that's the answer to my original question about incorporating this into a passive system like ORB-SLAM3. The planning logic is clean enough that it could sit on top of any reconstruction pipeline that exposes uncertainty estimates. TSDF would need a different entropy formulation, but the outer loop (sample candidates, score by expected gain, plan motion) transfers directly.
If you read this, thanks!
Feel free to reach out with any questions :)